PORTFOLIO
We offer very competent professionals with a strong understanding of graphs, relationships and technical infrastructure, backed by the NEO4J certification and years of integration experience using R, Python and Java.

We offer very competent professionals with a strong understanding of graphs, relationships and technical infrastructure, backed by the NEO4J certification and years of integration experience using R, Python and Java.
Hand gesture capabilities for the graph explorer.
As one of the selected project for the GSoC (Google Summer of Code) in 5 years (2009 – 2013), Gephi is an open-source network analysis and visualisation software package written in Java.
This video by Robert O’Leary shows how Leap Motion can be used to control a graph layout. This project developed on this concept by connecting Leap Motion to a complex large-scale graph using Gephi (gephi.org) as the platform for visualisation.
This video shows some data being loaded from the Securities and Exchange Commission public website, streamed to the browser, and rendered as a 3D WebGL graph. The camera in the 3D space can be controlled using the Leap Motion. LeapTrainer.js gestures are used to trigger layout algorithms that animate the graph nodes and connections into new positions.
Estimation of flood periods based on data from Bureau of Meteorology
Floods and drought situations have been always a major area of concern for Victoria. Some of the notable floods were in 1863, 1869, 1891 and then 1909, 1934, 1956, 1970 and 2010, 2011 and 2012. Although the fatalities were controlled but still had a very severe impacts for example Flood in 1934 (36 deaths, 6000 homeless and 400+ buildings damaged), 2010 Victorian flood (around 18 towns severely affected, 250 houses evacuated in one day, around 35 rivers were both fast and slow flooded), 2011 Victorian floods (51 affected communities, 1730 properties were flooded, total property damage of $2 Billions).
The project was conducted to answer the following questions:

When it comes to a statistical analysis, its importance in this area is increasing due to the unpredictable climatic and rainfall conditions. The rainfall characteristics for calculating the return period is multidimensional and hence requires a multivariate modelling techniques. The major requirement of conducting a multivariate or we can say bivariate in this case as the variables are 2, Severity and duration, is the fact that both the variables should be of same family of marginal density function (H. Vittala, 2015). Introduction of copula based analysis has paved a way to perform a more accurate analysis of these models as we don’t need to work on the assumptions of the variables having the same distribution. It joins different marginal distribution types to create a model and predicts the return period.


Association between some childhood behaviours that may lead to an addiction for the child in future
This project was conducted with the help of a Medical Practitioner who wanted to find out the association between some childhood behaviours that may lead to an addiction for the child in future.
Our team designed the questionnaire and conducted a research with the Adult addicts who came for a treatment and got some insight about their childhood behaviours. The research also extended to the parents to identify the similar traits in the answers.
The results picked up those traits that showed a strong association between the childhood indicators for an Adult who became a drug addict later. We are currently trying to survey a larger set of addicts and their families to gather a larger sample for validate the results in the above project.

Identifying the characteristics which are most responsible for the retention of customers
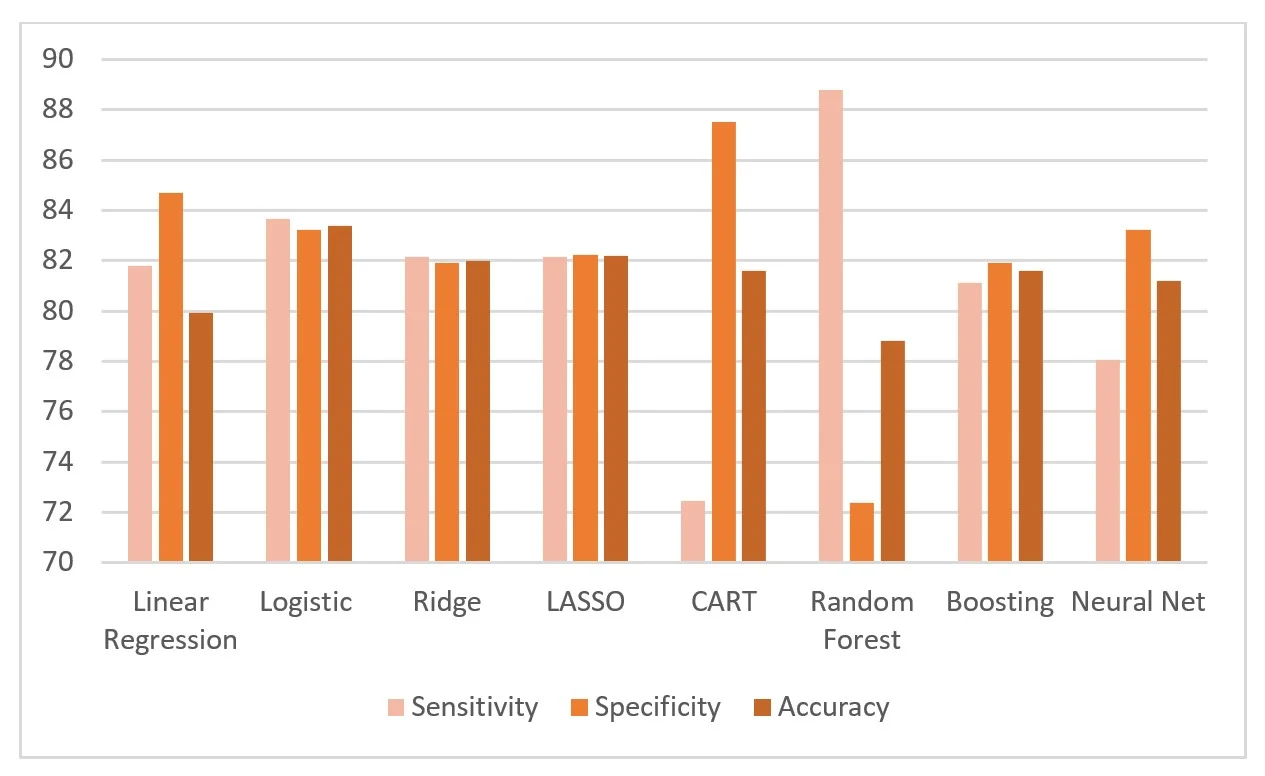
A comprehensive study was performed on the data provided by a company which organizes school trips. The primary objective of the study was to identify the characteristics which are most responsible for the retention of customers. The secondary objective was to identify the best predictive model to predict the customers’ response.
Different modeling techniques such as linear regression, logistic regression, ridge regression, LASSO regression, CART, random forest, neural network and boosting were applied on the school trip data. The relationship between the response variable and different parameters was established based on the findings of aforementioned models.
The findings of the study suggest that satisfaction and loyalty plays an important role in extending a relationship with a customer. It was found that logistic regression model performed the best in predicting the response of the customers. In addition, linear models outperformed nonlinear models for the data. Our study showed that complex models do not always provide the best predictions.

The study examines the impact of different parameters on retention using various statistical modeling and machine learning methodologies. Comparison of the performance of different statistical modeling methods such as linear regression, logistic, ridge and LASSO regression yields that logistic regression provides the best performance. Analyses performed using different machine learning methods such as CART, random forest, boosting and neural network highlights that response predicted by Boosting is the best among all the machine learning methods.
In addition, the comparison of all methods simultaneously unravelled that logistic regression, which is one of the simplest and oldest classification techniques provides the maximum predictive power. It also highlights that fancy and advanced algorithms do not always work better. Different predictive modelling techniques work better on various kinds of data. Without scrutinizing the data carefully, logical conclusions cannot be made. Logistic, ridge and LASSO regression techniques are linear models, whereas Random Forest, CART, Boosting and Neural Network are nonlinear models and the overall results show that linear models performance is almost equal or better than nonlinear models. However, different model performances will vary depending on the objective of the company i.e. whether they want to focus on top 20% or top 50% of the customers.

Ensembling of all models is a useful technique in determining robust predictions regarding a dataset. The ensembled model accuracy was found to be 82.8% which was higher than most of the models accuracy; only lower than the logistic regression accuracy. If the behaviour of data is not known and it is not sure which method would provide the best predictive method, ensembling of the models is a useful technique that can yield highly accurate predictions.
The analyses determined the most important parameters that affect the response of the customers. The findings confirm that customer satisfaction plays a prominent role in retention. NPS score and Travel with us next year parameters which describe the satisfaction level of the teachers came out to be the most important factors. Whether the customer is Existing or New also decides the retention of the customers. This parameter explains the loyalty of a customer; if a customer is loyal, he/she will definitely extend their relationship with the firm.
This work compared some statistical and machine learning techniques. More predictive modeling techniques such as K- Nearest Neighbour, Elastic Net, Non Linear Decision trees, Elastic Net, Support Vector Machine can be implemented in the future to study the behaviour of the data and to find more robust predictions.



